簡介
在很多年前的一次Code Review中,有大佬指出,方法的參數太多了,最好不要超過四個,對于當時還是萌新的我,雖然不知道什么原因,但聽人勸,吃飽飯,這個習慣也就傳遞下來了,直到參加工作很多年后,才明白這其中的緣由。
調用協定
在計算機編程中,調用協定(Calling Convention)是一套關于方法/函數被調用時參數傳遞方式,棧由誰清理和寄存器如何使用的規范。
- 參數傳遞方式
- 寄存器傳遞:將參數存入CPU寄存器,速度最快。
- 棧傳遞:將參數壓入調用棧,再依次從棧中取出,速度最慢
- 混合傳遞:前N個參數用寄存器,剩余參數用棧,速度適中
- 棧由誰清理
- Caller清理:調用函數后由調用方負責恢復棧指針(如C/C++的
__cdecl)。 - Callee清理:被調用函數返回前自行清理棧(如x64的默認協定)。
- 寄存器如何使用
- 易變寄存器(Volatile Registers):函數調用時可能被修改的寄存器(如x64的
RAX、RCX、RDX),調用方需自行保存這些寄存器的值。 - 非易變寄存器(Non-Volatile Registers):函數必須保存并恢復的寄存器(如x64的
RBX、RBP、R12-R15)。
x86架構混亂的調用協定
x86架構發展較早,因此調用協定野蠻生長,有多種調用協定
| 協定名稱 | 參數傳遞方式 | 棧清理 | 適用場景 |
|---|
__cdecl | 通過棧傳遞(右→左) | 調用者清理棧 | C/C++默認,支持可變參數 |
__stdcall | 通過棧傳遞(右→左) | 被調用者清理棧 | Windows API(如Win32) |
__fastcall | 前兩個參數通過寄存器,剩余通過棧(右→左) | 被調用者清理棧 | 高性能場景 |
__thiscall | this指針通過寄存器, 剩余通過棧(右→左) | 被調用者清理棧 | C++類成員函數 |
眼見為實


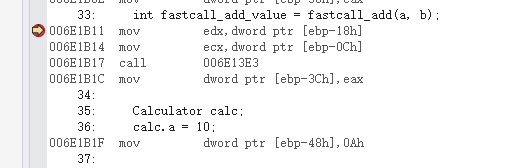
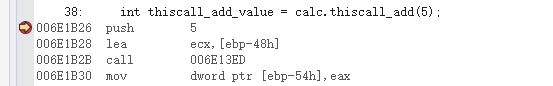
可以看到,cdecl,stdcall是通過壓棧的方式將參數壓入棧中,而fastcall直接賦值給寄存器,并無壓棧操作
點擊查看代碼
#include <iostream>
int __cdecl cdecl_add(int a, int b) {
return a + b;
}
int __stdcall stdcall_add(int a, int b) {
return a + b;
}
int __fastcall fastcall_add(int a, int b) {
return a + b;
}
class Calculator {
public:
int __thiscall thiscall_add(int b) {
return this->a + b;
}
int a;
};
int main()
{
int a = 10, b = 5;
int cdecl_add_value = cdecl_add(a, b);
int stdcall_add_value = stdcall_add(a, b);
int fastcall_add_value = fastcall_add(a, b);
Calculator calc;
calc.a = 10;
int thiscall_add_value = calc.thiscall_add(5);
}
x64的大一統
而在x64架構下,為了解決割裂的調用協定,windows與linux實現了統一。
| 協定名稱 | 參數傳遞方式 | 棧清理 | 適用場景 |
|---|
MS x64 | 前4個參數通過寄存器,剩余通過棧(左→右) | 被調用者清理棧 | Windows x64程序 |
System V AMD64 | 前6個參數通過寄存器,剩余通過棧(左→右) | 被調用者清理棧 | Unix/Linux x64程序 |
眼見為實

linux下暫無圖(因為我懶),大概就是這意思,自行腦補
點擊查看代碼
#include <stdio.h>
int add(int a, int b, int c, int d, int e) {
return a + b + c + d + e;
}
int main() {
int result = add(1, 2, 3, 4, 5);
return 0;
}
C#中使用哪種調用協定?

C#在x86下,有自己獨特的調用協定
| 協定名稱 | 參數傳遞方式 | 棧清理 | 適用場景 |
|---|
Standard | 前兩個參數通過寄存器,剩余通過棧(左→右) | 被調用者清理棧 | C#靜態方法 |
HasThis | 前兩個參數通過寄存器(第一個為This),剩余通過棧(左→右) | 被調用者清理棧 | C#實例方法 |
在x64形成實現統一,與操作系統保持一致
眼見為實



注意寄存器與棧是兩片獨立運行的區域,光從匯編代碼,很容易陷入誤區,就拿上圖來說,從上往下閱讀匯編,你會發現參數傳遞的順序是30(1Eh),40(28h),50(32h),10(0Ah),20(14h)。明顯不對,這是因為一個是寄存器,一個是線程棧,這是兩個不相關的區域,誰前誰后都不違反從左到右的規定。不能死腦筋,寄存器與棧之間是存在位置無關性的。
/*這種順序也是正確的,寄存器是寄存器,棧是棧,匯編的順序不影響他們的位置無關性,因為是兩片獨立運行的區域*/
push 1Eh
mov ecx,0Ah
push 28h
mov edx,14h
push 32h
點擊查看代碼
internal class Program
{
static void Main(string[] args)
{
var t = new Test();
var sum = t.Add(10, 20, 30, 40, 50);
var sum2 = Test.StaticAdd(10, 20, 30, 40, 50);
Console.ReadKey();
}
}
public class Test
{
public int Add(int a, int b, int c, int d, int e)
{
var sum = a + b + c + d + e;
return sum;
}
public static int StaticAdd(int a, int b, int c, int d, int e)
{
var sum = a + b + c + d + e;
return sum;
}
}
結論
可以看到,在Windows x64下,如果方法的參數<=4 那么就就完全避免了棧傳遞的開銷,實現性能最佳化。
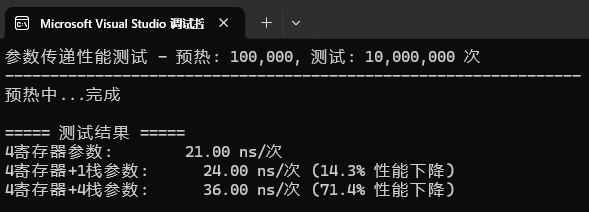
在linux下,參數為<=6,根據木桶效應,取4為最佳。
當然,此文不是讓你嚴格遵守此規則,隨著CPU性能的發展,在微服務集群大行其道的今天。這點性能差距可以忽略不計,權當飯后消遣,補充冷知識,好讓你在未來的Code Review中,沒活硬整.
點擊查看代碼
internal class Program
{
static void Main(string[] args)
{
ParameterPassingBenchmark.Run();
}
}
public class ParameterPassingBenchmark
{
private const int WarmupIterations = 100000;
private const int BenchmarkIterations = 10000000;
private const int BatchSize = 1000;
private static readonly Random _random = new Random(42);
[MethodImpl(MethodImplOptions.NoInlining | MethodImplOptions.NoOptimization)]
public static int Register4Params(int a, int b, int c, int d) => a + b + c + d;
[MethodImpl(MethodImplOptions.NoInlining | MethodImplOptions.NoOptimization)]
public static int Stack1Param(int a, int b, int c, int d, int e) => a + b + c + d + e;
[MethodImpl(MethodImplOptions.NoInlining | MethodImplOptions.NoOptimization)]
public static int Stack4Params(int a, int b, int c, int d, int e, int f, int g, int h)
=> a + b + c + d + e + f + g + h;
public static void Run()
{
Console.WriteLine($"參數傳遞性能測試 - 預熱: {WarmupIterations:N0}, 測試: {BenchmarkIterations:N0} 次");
Console.WriteLine("----------------------------------------------------------------");
var inputData = GenerateInputData();
Warmup(inputData);
var reg4Time = Measure(() => Register4ParamsTest(inputData));
var stack1Time = Measure(() => Stack1ParamTest(inputData));
var stack4Time = Measure(() => Stack4ParamsTest(inputData));
Console.WriteLine("\n===== 測試結果 =====");
Console.WriteLine($"4寄存器參數: {reg4Time,12:N2} ns/次");
Console.WriteLine($"4寄存器+1棧參數: {stack1Time,10:N2} ns/次 ({((double)stack1Time / reg4Time - 1) * 100:F1}% 性能下降)");
Console.WriteLine($"4寄存器+4棧參數: {stack4Time,10:N2} ns/次 ({((double)stack4Time / reg4Time - 1) * 100:F1}% 性能下降)");
}
private static (int[], int[], int[]) GenerateInputData()
{
var data4 = new int[BenchmarkIterations * 4];
var data5 = new int[BenchmarkIterations * 5];
var data8 = new int[BenchmarkIterations * 8];
for (int i = 0; i < BenchmarkIterations; i++)
{
for (int j = 0; j < 4; j++) data4[i * 4 + j] = _random.Next();
for (int j = 0; j < 5; j++) data5[i * 5 + j] = _random.Next();
for (int j = 0; j < 8; j++) data8[i * 8 + j] = _random.Next();
}
return (data4, data5, data8);
}
private static void Warmup((int[], int[], int[]) inputData)
{
Console.Write("預熱中...");
var (data4, data5, data8) = inputData;
for (int i = 0; i < WarmupIterations; i++)
{
Register4Params(data4[i * 4], data4[i * 4 + 1], data4[i * 4 + 2], data4[i * 4 + 3]);
Stack1Param(data5[i * 5], data5[i * 5 + 1], data5[i * 5 + 2], data5[i * 5 + 3], data5[i * 5 + 4]);
Stack4Params(data8[i * 8], data8[i * 8 + 1], data8[i * 8 + 2], data8[i * 8 + 3],
data8[i * 8 + 4], data8[i * 8 + 5], data8[i * 8 + 6], data8[i * 8 + 7]);
}
Console.WriteLine("完成");
}
private static long Measure(Func<long> testMethod)
{
GC.Collect();
GC.WaitForPendingFinalizers();
GC.Collect();
testMethod();
var stopwatch = Stopwatch.StartNew();
long result = testMethod();
stopwatch.Stop();
if (result == 0) Console.WriteLine("警告: 結果為0,可能存在優化問題");
long totalNs = stopwatch.ElapsedTicks * 10000000L / Stopwatch.Frequency;
return totalNs / (BenchmarkIterations / BatchSize);
}
private static long Register4ParamsTest((int[], int[], int[]) inputData)
{
var (data4, _, _) = inputData;
long sum = 0;
int index = 0;
for (int i = 0; i < BenchmarkIterations / BatchSize; i++)
{
for (int j = 0; j < BatchSize; j++)
{
sum += Register4Params(
data4[index++],
data4[index++],
data4[index++],
data4[index++]
);
}
}
return sum;
}
private static long Stack1ParamTest((int[], int[], int[]) inputData)
{
var (_, data5, _) = inputData;
long sum = 0;
int index = 0;
for (int i = 0; i < BenchmarkIterations / BatchSize; i++)
{
for (int j = 0; j < BatchSize; j++)
{
sum += Stack1Param(
data5[index++],
data5[index++],
data5[index++],
data5[index++],
data5[index++]
);
}
}
return sum;
}
private static long Stack4ParamsTest((int[], int[], int[]) inputData)
{
var (_, _, data8) = inputData;
long sum = 0;
int index = 0;
for (int i = 0; i < BenchmarkIterations / BatchSize; i++)
{
for (int j = 0; j < BatchSize; j++)
{
sum += Stack4Params(
data8[index++],
data8[index++],
data8[index++],
data8[index++],
data8[index++],
data8[index++],
data8[index++],
data8[index++]
);
}
}
return sum;
}
}






 400 186 1886
400 186 1886


